为什么在 ORM 层做缓存,而不是 DB 层
ORM 能有效地提高程序员的开发效率,程序员更喜欢操作对象而不是数据库,他们不关心也不想手写一堆 SQL 语句,毕竟一个公司里普通程序员要占多数,他们并不是非常熟悉数据库,写出来的 SQL 执行效率也肯定会有这样那样的问题。
如果让程序员去操作对象,这就是他们的强项了:定义关系、使用 ORM 的方法和属性、获取/遍历结果等等。同时 ORM 又可以在内部对 SQL 语句及对象之间的关系进行优化,尽量保证 SQL 高效地执行,甚至可以透明地加个缓存。这样一个双赢的结果,何乐而不为呢。
如果是一些比较复杂的查询语句,只能通过写 SQL 语句来实现,这样的话,可以在语句的执行段外面套一层缓存判断,如:
<?php
$result = $memcache->get('isobamapresident'); // fetch
if ($result === false)
{
// do some database heavy stuff
$db = DB::getInstance();
$votes = $db->prepare( "SELECT COUNT(*) FROM VOTES WHERE vote = 'OBAMA'" )->execute();
$result = ($votes > (USA_CITIZEN_COUNT / 2)) ? 'Sure is!' : 'Nope.'; // well, ideally
$memcache->set('isobamapresident', $result, 0);
}透明地插入缓存
所谓透明缓存,就是用户正常使用 ORM,获取 ORM 的查询结果。而事实上 ORM 的结果集很可能是来自缓存而不是数据库。
<?php
//获取1小时前发布的文章
$time = time() - 86400;
ORM::factory('article')->where('created', '>', $time)->findAll();
//正常的结果是通过执行以下SQL语句返回的
//SELECT * FROM article WHERE created > $time
//但实际上可能是从Memcache中读取的结果
$memcache = new Memcache();
$memcache->connect('memcache_host', 11211);
$memcache->get('some_key');这样一来,php 代码不用改变,但因为是从缓存中读取,所以数据的获取速度有保障,同时也减轻了数据库的压力,又是一个双赢的局面。
当然愿望是美好的,现实是残酷的,如果要达到上面所说的效果,需要费不少周折。
数据库架构
在设计 ORM 的缓存前,先了解以下数据库的大致架构。以 netlog 的数据库架构变迁为例:
单数据库

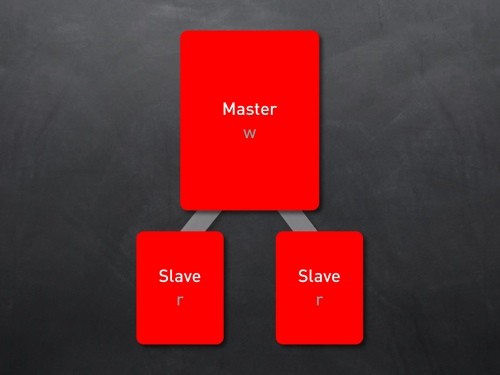
主库+从库
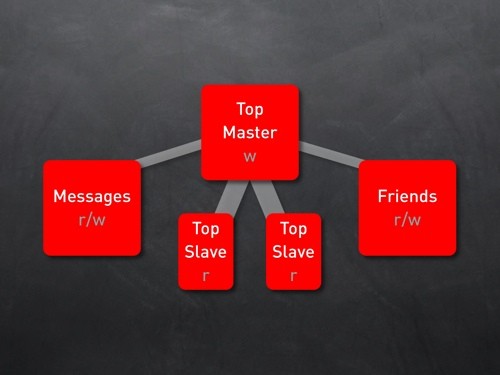
保持主库+从库的架构,把读写最频繁的几个表分到单独的数据库服务器
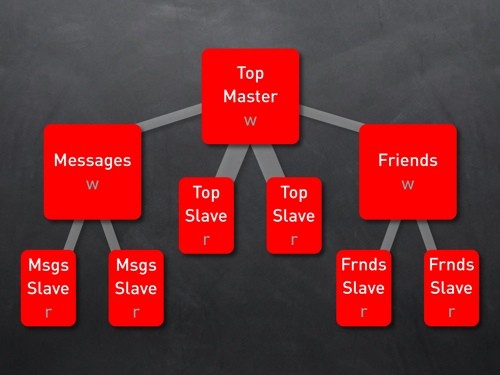
把那几个读写最频繁的表也分成主从
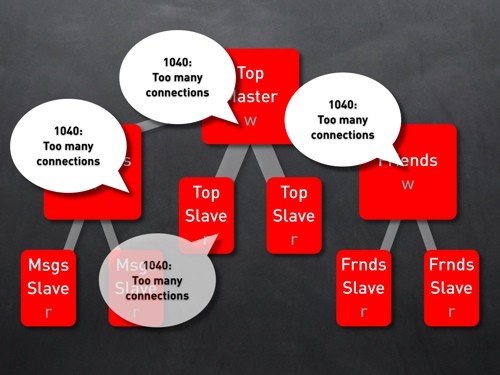
出现了 1040 too many connections
Sharding(水平分区)

数据库服务器/数据库/分区
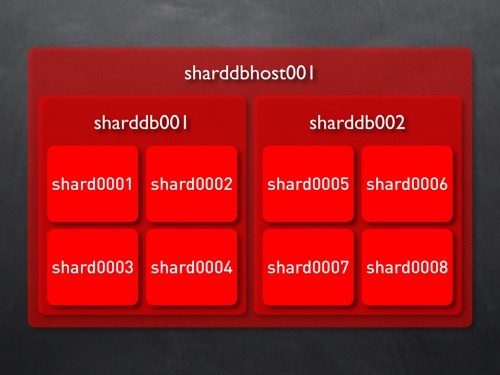
这样基本上就可以应付正常的访问了,如果哪个表数据量过大或连接过多,就 Sharding 一下。但随之而来的问题也很明显,比如:
<?php
//没有分区之前,可以通过下面几段代码来获取数据
$db = DB::getInstance();
$db->prepare("SELECT title, message FROM BLOG_MESSAGES WHERE userid = {userID}");
$db->assignInt('userID', $userID);
$db->execute();
$results = $db->getResults();
//假设将BLOG_MESSAGES按照用户id分配到了不同的分区上,上面的代码就需要做一些改动
//最简单的就是在getInstance时把用户的id传过去,让ORM内部去找分区,相当于路由
$db = DB::getInstance($userID);如何对数据进行分片
当要对数据进行分片时,应该考虑这两个问题:使用表的哪一列(sharding key)作为分割的依据;使用怎样的分割算法(sharding scheme)。使用哪个 key 要看具体的应用。以博客为例,如果想要现实每个用户的博客,那么 userID 就可以作为 sharding key。如何根据 sharding key 来找到对应的分区一般有三种方法:取模(求余)、数据量、映射表。假设采用映射表的方法,如果要获取用户的博客,先要到映射表里找到该 userID 对应的分区,再从分区中找到 userID 对应的博客列表。随之而来的问题是:
不能执行跨分区查询
如果要从不同的分区获取数据,就不能通过 JOIN/GROUP BY/ORDER BY/LIMIT 来实现了。比如:
// 获取最新的10条博客
SELECT * FROM BLOG_MESSAGES ORDER BY created DESC LIMIT 0, 10;
// 如果数据在多个分区中,上面这条查询就失效了要解决这个问题,最好从设计上就避免这些查询语句。也可以通过冗余来实现。
数据一致性得不到保障
因为会在多个数据库之间更新数据,如果要保证数据一致性,就要实现分布式事务。
也可以通过一个小技巧来模拟分布式事务,比如有两台数据库服务器,这时可以先开启一个事务,但只在保证两台服务器都正常的情况下才一一提交事务。当然两次事务的提交也会有延迟,但相对来说更加靠谱。
保持分区平衡
如果基于用户 ID 进行分区,可能会出现分区之间的不平衡,比如一些活跃的用户都被分到了同一分区,而沉默用户被分到了另一个分区,这时量贩额分区的压力明显不一样。所以分区的算法很重要。
备份策略
因为数据在不同的分区中,备份策略就不想以前那么简单了。
ORM 的缓存实现
先声明一下,ORM 的缓存不能解决 JOIN 或者复杂的 SQL 查询,其实如果考虑到将来会有分区的可能,就应该在设计表时避免 JOIN 语句。因为复杂的 SQL 相对来说占的少数,甚至可以对这些 SQL 单独制定缓存策略。
先不考虑分区,假设有一个用户表和博客表,要达到以下目标:
- 缓存每一条博客记录,更新博客时,更新缓存
- 缓存每个用户的博客列表,用户更新博客时,更新该列表
- 程序员使用 ORM 时不需要考虑缓存
缓存行实现
缓存行还是比较简单的,用户查询某个 id 时,缓存该行内容,下次就可以直接读取缓存了。
如果内容被更新/删除了,缓存也同时更新/删除。
缓存列实现
<?php
//如果在find/findAll里传入了参数,则该参数即为key
ORM::factory('article')->where('user_id', '=', '2')->and_where('created', '>', time() - 86400)->findAll(2);
//上面的代码会在Model内部生成一个结构化的字符串,该字符串及对应的值将被放入缓存中
{table_name}-{key}-{md5(sql)}
//类似这样
article-2-c81e728d9d4c2f636f067f89cc14862c
//如果没有传参数,{key}就不会被替代
article-{key}-c81e728d9d4c2f636f067f89cc14862c
//首次执行此代码时,ORM内部会先去缓存中找上面的结构化字符串,没有找到,就会执行SQL语句,然后把返回的结果的id放到缓存中
//这就是要放到缓存中的数据,下次如果再执行此SQL,直接从缓存中获取id(1,43,50),然后再从缓存中获取这些id对应的行内容
//注意到这里有个revision,这是将来要判断该缓存是否已过期的关键。
'article-2-c81e728d9d4c2f636f067f89cc14862c' => array(
'revision' => 1294476790,
'data' => [1, 43, 50],
);
//同时还会生成另一组数据,就是revision
'article-2-revision' => 1294476777,
//如果作者又更新了一篇博客,则上面的查询语句结果就发生了变化。
ORM::factory('article')->values(array(...))->save(2);
//ORM会找到缓存中的一组revision数据,同时更新它
'article-2-revision' => 1294476888,
//如果没有提供key,那就是
'article-{key}-revision' => 1294476888,
//下次再执行上面的ORM查询代码时,会先去查找'article-2-revision'的版本,然后跟'article-2-c81e728d9d4c2f636f067f89cc14862c'的版本号比较,如果前一个版本号>后一个版本号,表示数据有改变,缓存已过期,这时就需要重新执行SQL语句,并更新'article-2-c81e728d9d4c2f636f067f89cc14862c'这个字符串的版本号。如果比较结果是前一个版本号<=后一个版本号,那就直接从缓存中读取。
ORM 的路由
上面说的是数据没有分区的情况,如果数据被分区了的话,还要在 ORM 内部实现路由功能。
<?php
ORM::factory('articles')->where('created', '>', time()-86400)->findAll();假设文章通过某种算法,被分在了不同的分区上,上面这个 ORM 编译出来的 SQL 是无法运行的。但又不能让程序员来关心分库分表的事,这时就可以在 ORM 内部实现路由机制,在具体的 Model 层实现路由算法。
<?php
class Model_Article extends ORM
{
protected function _route()
{
//这里可以实现具体算法,改变ORM的一些属性,从而影响SQL的编译
}
}参考: