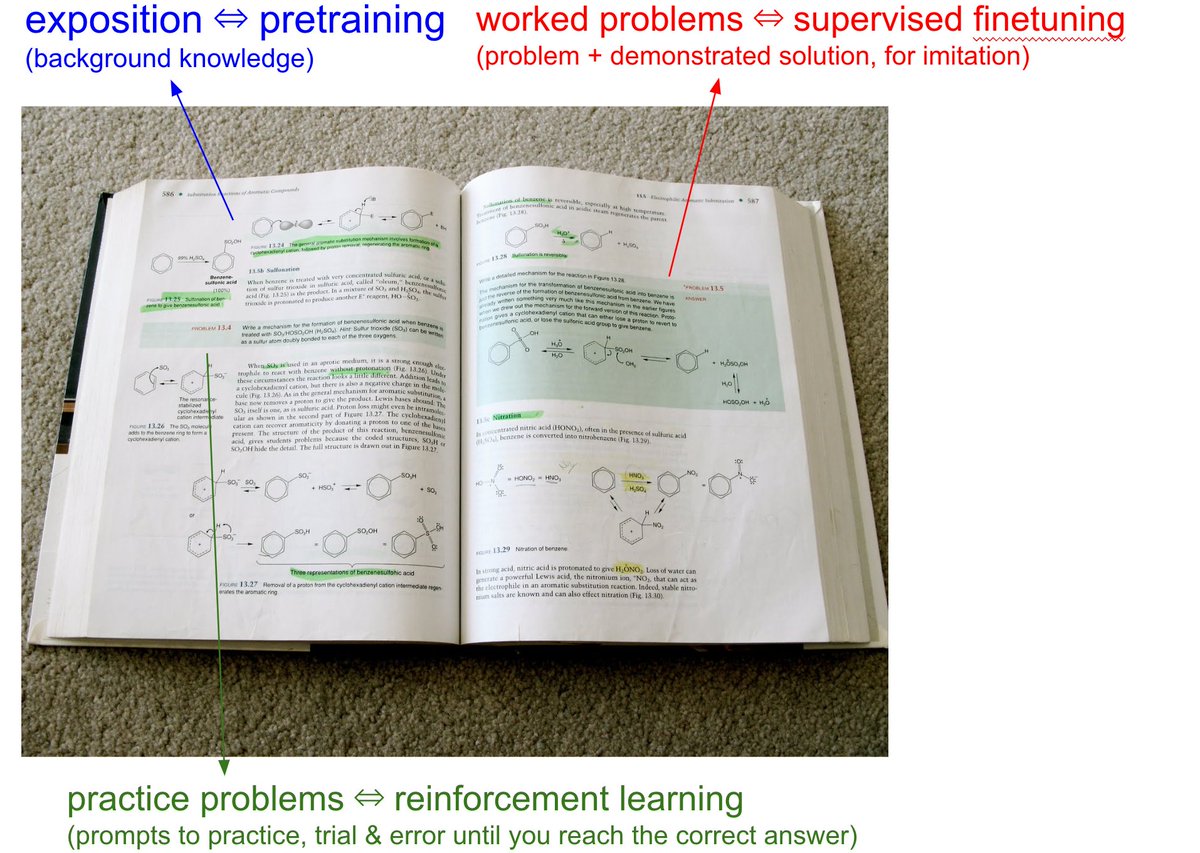
We have to take the LLMs to school. When you open any textbook, you'll see three major types of information: 1. Background information / exposition. The meat of the textbook that explains concepts. As you attend over it, your brain is training on that data. This is equivalent to pretraining, where the model is reading the internet and accumulating background knowledge. 2. Worked problems with solutions. These are concrete examples of how an expert solves problems. They are demonstrations to be imitated. This is equivalent to supervised finetuning, where the model is finetuning on "ideal responses" for an Assistant, written by humans. 3. Practice problems. These are prompts to the student, usually without the solution, but always with the final answer. There are usually many, many of these at the end of each chapter. They are prompting the student to learn by trial & error - they have to try a bunch of stuff to get to the right answer. This is equivalent to reinforcement learning. We've subjected LLMs to a ton of 1 and 2, but 3 is a nascent, emerging frontier. When we're creating datasets for LLMs, it's no different from writing textbooks for them, with these 3 types of data. They have to read, and they have to practice.
一个好的学习系统应该是不是应该这样:
- AI 生成特定的知识点,用费曼的方式来讲解。
- 自动生成该知识点对应的测验。
- 如果测验结果错误,则放出相关的的知识点以及正确的解题思路。
- 经过多轮测验,AI 确保目标用户掌握该知识点之后,再重复 1.
针对用户进行定制化学习,提高学习效率。